BERT per Sentiment Analysis: come un Transformer legge davvero
Il post precedente costruiva image captioning con un encoder CNN e un decoder LSTM. Era il mondo pre-transformer. Questo è quello che è venuto dopo.
Abbiamo fatto fine-tuning di BERT su recensioni di film per classificare il sentiment, positivo o negativo. Un task semplice in superficie. Ma per capire perché funziona (e dove fallisce), devi capire ogni layer. Quindi passiamo tutto in rassegna: tokenizer, embedding, self-attention, multi-head, feed-forward, 12 encoder layer uno sopra l'altro. Senza scorciatoie.
Cos'è BERT
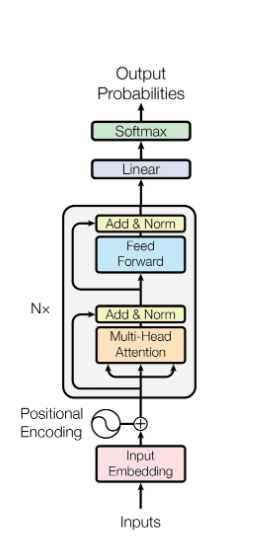
BERT è un transformer encoder-only. Non genera testo, lo legge e costruisce una rappresentazione contestualizzata dell'input. Tre stage:
- Tokenizer + Positional Encoding: frase grezza → vettori numerici
- Transformer Encoder: 12 layer di self-attention + feed-forward
- Classification Head: token CLS → softmax → Positivo/Negativo
Stage 1: Tokenizer
Il BertTokenizer pre-addestrato fa diverse cose alla tua frase:
- Converte tutto in minuscolo
- Divide per punteggiatura
- Applica WordPiece: le parole conosciute rimangono intere, le parole sconosciute vengono divise in subword (es. "film" rimane intero, una parola sconosciuta diventa "mo" + "##vie"). Il prefisso
##significa "questa è una continuazione". L'informazione sulla divisione non va persa. - Aggiunge token speciali:
[CLS]all'inizio,[SEP]alla fine - Converte i token in ID interi dal vocabolario
![BertTokenizer: frase → minuscolo → subword WordPiece → [CLS]/[SEP] → ID interi](/images/blog/bert-sentiment/tokenizer.png)
Il tokenizer è pre-addestrato. Non lo tocchiamo. Lo usiamo e basta.
Stage 2: Embedding
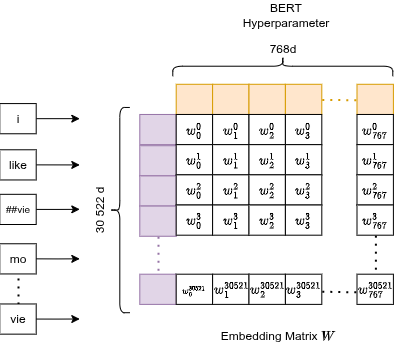
Token Embedding
Ogni ID token viene mappato a un punto in uno spazio a 768 dimensioni. Questo è l'iperparametro di default di BERT: 768 numeri per token.
È semplicemente una lookup table apprendibile (matrice di dimensione vocab_size × 768). Matematicamente, selezionare la riga 3185 equivale a moltiplicare l'intera matrice di embedding per un vettore one-hot con un 1 alla posizione 3185. Un'operazione puramente lineare.
Gli embedding vengono addestrati tramite backpropagation: quando il gradiente arriva qui, dice "il vettore per il token X dovrebbe spostarsi in questa direzione." L'ottimizzatore (AdamW) aggiorna direttamente quella riga.
Risultato: token semanticamente simili finiscono con vettori vicini nello spazio 768-d.
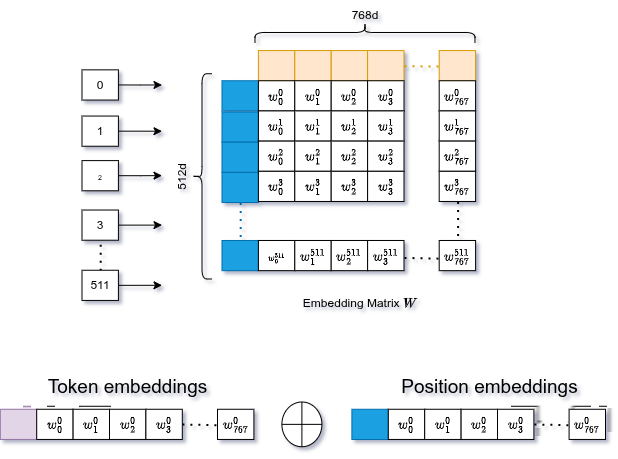
Positional Embedding
I transformer non hanno nozione di ordine. Processano tutti i token in parallelo. Per risolvere questo, si generano un secondo set di embedding per la posizione di ogni token (0, 1, 2, ...) e li si aggiunge agli embedding dei token.
Stesso meccanismo: lookup table apprendibile, stessa dimensione 768-d. La posizione 0 ottiene il suo vettore, la posizione 1 il suo, e così via.
L'embedding combinato passa poi per LayerNorm (stabilizza il training) e Dropout (previene l'overfitting).
Stage 3: Transformer Encoder
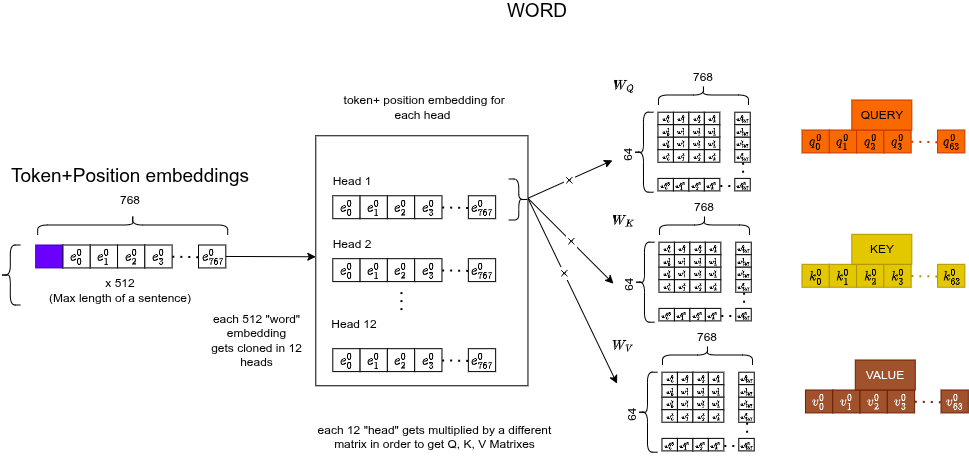
Q, K, V
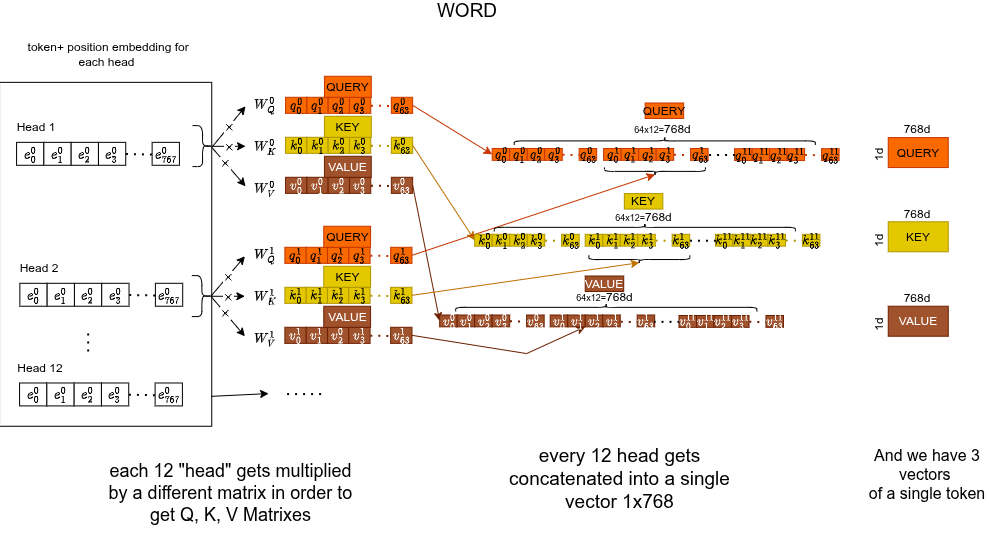
L'embedding 768-d di ogni token viene moltiplicato per tre matrici di pesi apprese separatamente ($768 \times 64$), producendo tre vettori a 64-d:
- Query : "cosa sto cercando?"
- Key : "cosa offro come contesto?"
- Value : "quale informazione porto effettivamente?"
Es. Query: "sto cercando un verbo". Key: "sono un soggetto". Value: "la parola film".
Q, K, V per un singolo token:
E sull'intera sequenza:
Vista a livello di frase:
Multi-Head Attention (12 teste)
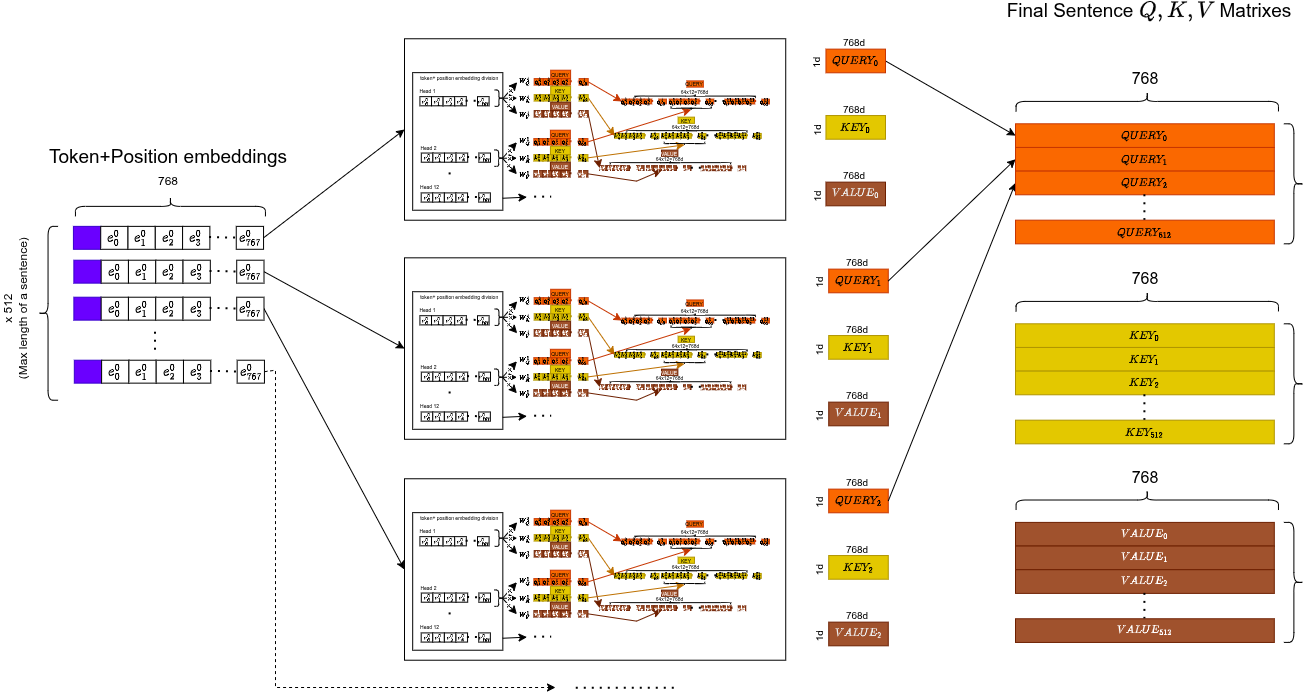
Non lo facciamo una sola volta. Lo facciamo 12 volte in parallelo, ciascuna con matrici di pesi diverse. Ogni testa si specializza in un "macro-settore" diverso della comprensione: grammatica, coreferenza, sinonimi, contesto, posizione, ecc.
Il modello impara quale testa si specializza in cosa. Non è hardcoded. La parallelizzazione è un effetto collaterale gratuito.
Attention Score
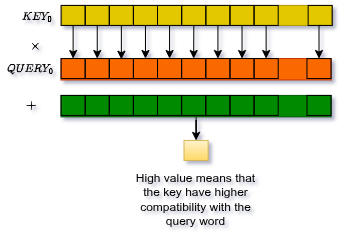
Per ogni testa, l'attention score tra il token e il token è il prodotto scalare dei loro vettori query e key:
La scalatura (radice quadrata della dimensione della testa) impedisce che i prodotti scalari crescano troppo, il che spingerebbe la softmax in regioni con gradienti quasi nulli.
Perché funziona ? Se quello che un token cerca (Query) e quello che un altro offre (Key) puntano nella stessa direzione, il loro prodotto scalare è alto → alto peso di attenzione. Se puntano in direzioni opposte, quasi zero.
Esempio classico: la parola "banca".
- : "ho bisogno di contesto. Sono soldi o natura?"
- : "offro contesto natura"
- : "offro contesto istituzione"
L'alto prodotto scalare tra e risolve l'ambiguità.
Attention Matrix
Applica la softmax all'intera matrice : ottieni una matrice dove ogni riga somma a 1. La riga dice quanto ogni altro token contribuisce alla rappresentazione aggiornata del token .
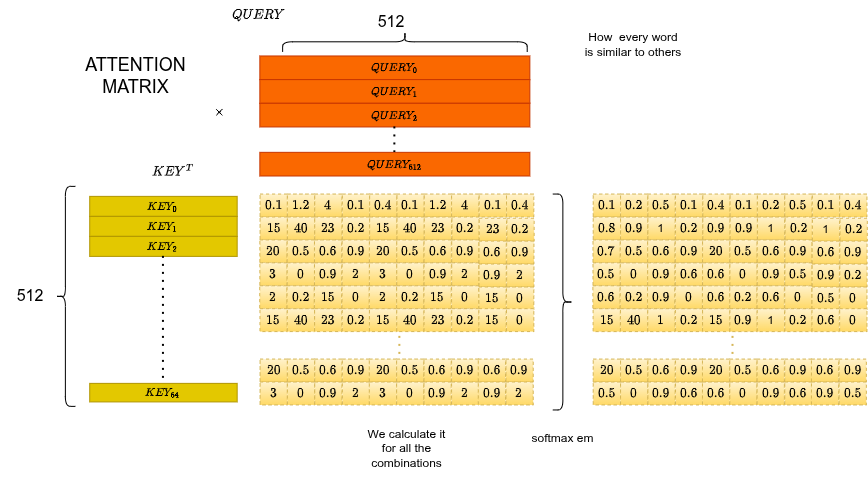
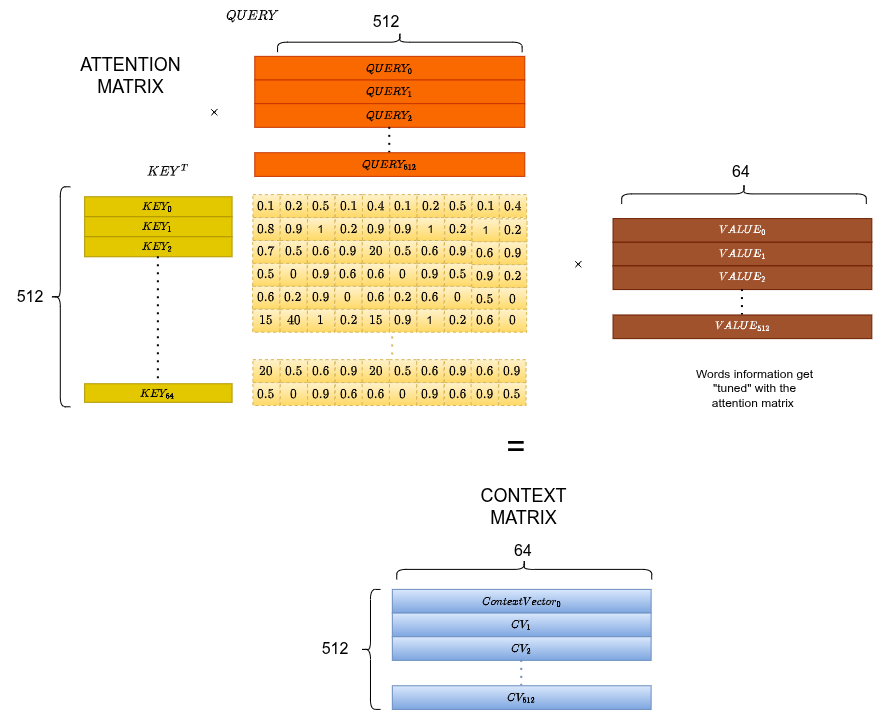
Context Matrix
Moltiplica per per ottenere la rappresentazione pesata per contesto:
Ogni riga è ora un embedding del token arricchito dall'attenzione verso tutti gli altri token.
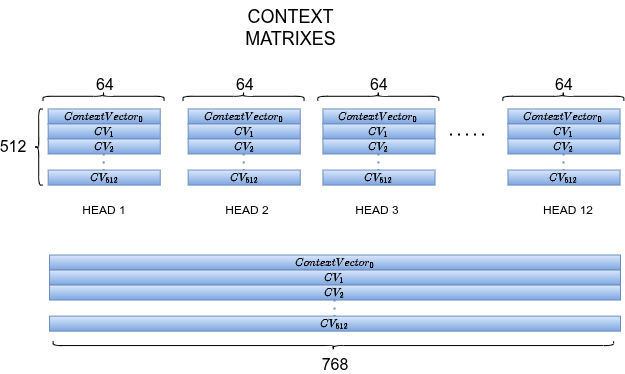
Concatenazione di Tutte le Teste
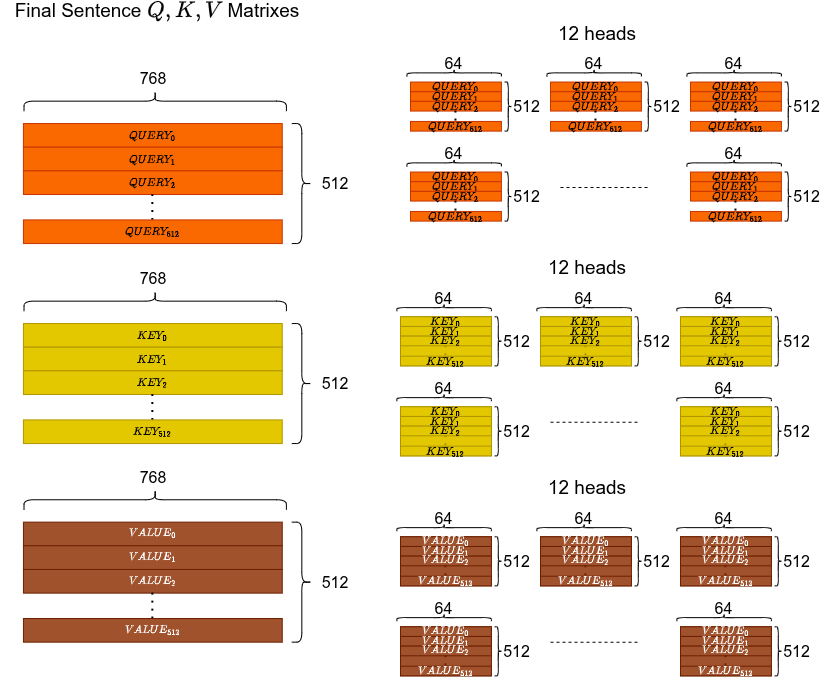
Ciascuna delle 12 teste produce la propria context matrix (64-d per token). Concatena tutte e 12 → torna a dimensioni. Poi passa per una proiezione lineare finale.
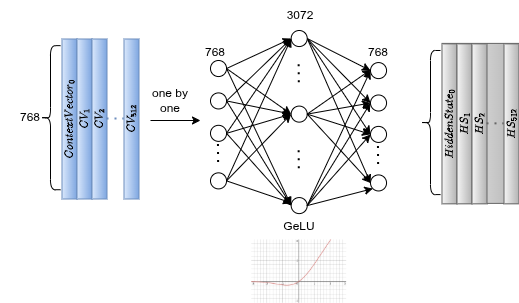
Feed-Forward Network
Dopo l'attenzione, ogni token passa indipendentemente per una FFN a due layer:
L'espansione (768 → 3072, 4×) amplifica i pattern e permette alla rete di combinare le feature in uno spazio ad alta dimensione. GeLU introduce non-linearità con gradienti più smooth di ReLU. La compressione riporta a 768-d. Il Dropout previene la co-adattazione dei neuroni.
Viene applicata per token, indipendentemente. Nessuna interazione cross-token qui, quella era compito dell'attenzione.
12 Layer Encoder
Il blocco Attention + FFN viene ripetuto 12 volte. Tra ogni sotto-layer: connessione residua (input + output) e LayerNorm. Le connessioni residue prevengono il gradient collapse in profondità.
Dropout dopo l'attenzione, dopo la FFN e dopo gli embedding ovunque.
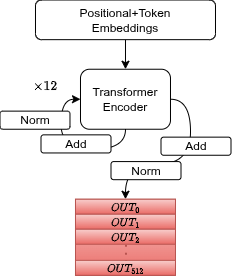
Stage 4: il token CLS
[CLS] è un token speciale preposto a ogni sequenza di input. Non ha significato intrinseco. È una lavagna pulita. Ma dopo 12 layer di self-attention, ha prestato attenzione a ogni altro token nella sequenza. Alla fine dell'encoder, l'embedding CLS ha aggregato il contesto semantico completo della frase.
È quello che usiamo per la classificazione.

Classification Head
Un pooler (un layer denso) trasforma l'embedding CLS (768-d) attraverso un'attivazione tanh. Poi un layer lineare finale lo mappa in 2 output (Positivo / Negativo). La softmax converte i logit in probabilità.

Training
Dataset: IMDB Large Movie Review Dataset, 4.500 recensioni reali campionate:
- 3.200 campioni di training (80%)
- 800 campioni di validazione (20%)
- 500 campioni di test (held out)
Loss: Cross Entropy sui logit a 2 classi vs. etichette reali.
Flusso backprop: errore alla classification head → pooler → 12 encoder layer → e pesi FFN aggiornati ad ogni layer → fino alla lookup table degli embedding.
Facciamo fine-tuning dell'intero modello, non solo della head. Ogni peso si aggiusta.
Overfitting e il Problema del Sarcasmo
Addestriamo per ~15 epoch. Intorno all'epoch 3, la validation loss smette di diminuire. Il modello fa overfitting.
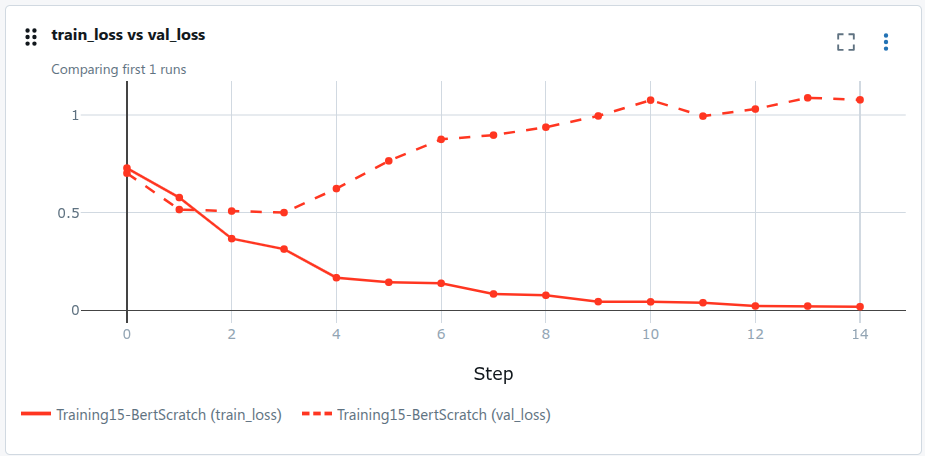
E c'è un problema più difficile. Il modello fallisce completamente sul sarcasmo:
"Great movie, if you enjoy watching paint dry for two hours."→ classificato come Positivo.
Il modello ha imparato "Great" → segnale positivo, senza capire il contesto ironico che segue. Questo è un problema di dati, non di modello.
Fix: Generazione di Dati Sintetici
Abbiamo generato recensioni sarcastiche e ironiche sintetiche usando Qwen3 Instruct (Q4, in esecuzione locale). L'obiettivo: insegnare al modello che "Great" può essere negativo nel contesto giusto.
Il modello fa ancora overfitting, ma le prestazioni sulla validazione sono migliorate. Ci fermiamo ancora intorno all'epoch 3, ma il confine decisionale è più netto.
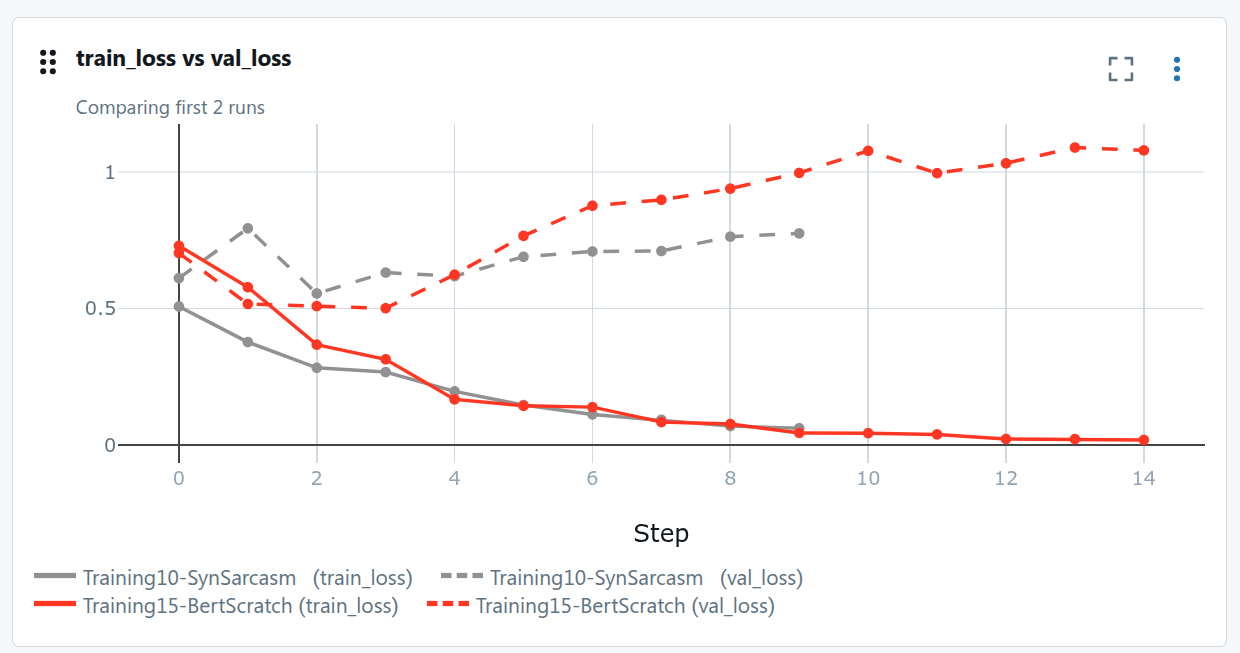
Dopo l'aggiunta di dati sintetici:
| Input | Prima | Dopo |
|---|---|---|
"Great movie, if you enjoy watching paint dry for two hours." |
Positivo | Negativo |
"The visual effects were stunning, but the plot made zero sense." |
Positivo | Negativo |
"I wish I knew what beautiful movie I just watched." |
Positivo | Negativo |
Il terzo è sottile. "I wish I knew" implica incertezza e delusione. I dati sintetici hanno spinto il modello a capire quel tipo di costruzione invertita.
TL;DR
- BertTokenizer: frase → subword WordPiece → ID interi +
[CLS]/[SEP] - Token + Positional embedding: ID → vettori 768-d, sommati, LayerNorm + Dropout
- 12 × (Multi-Head Attention + FFN): ogni token presta attenzione a tutti gli altri, 12 teste si specializzano, è l'operazione centrale
- Il token CLS aggrega il contesto dell'intera frase dopo 12 encoder layer
- Classification head: pooler + tanh + linear → 2 logit → softmax
- Overfitting dopo l'epoch 3 su IMDB. Il sarcasmo è il caso difficile.
- I dati sintetici da un LLM locale risolvono il fallimento sul sarcasmo