Blog
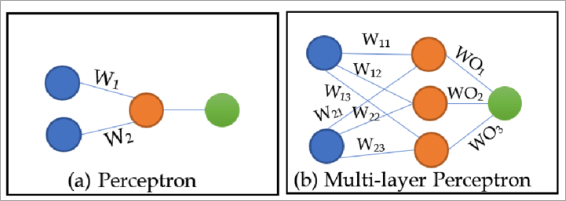
MLP da zero: 98% di accuratezza sulla classificazione del cancro, senza Keras
Abbiamo costruito un Multi-Layer Perceptron da zero, nessun framework di deep learning, e fatto una grid search su 20 configurazioni sul dataset Breast Cancer Wisconsin. 98.25% di accuratezza. Ecco la matematica, la struttura del codice e cosa ti dicono i risultati.
Leggi →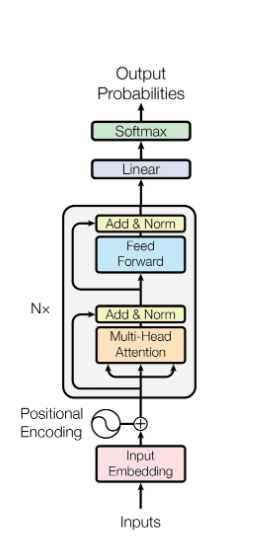
BERT per Sentiment Analysis: come un Transformer legge davvero
Abbiamo fatto fine-tuning di BERT su recensioni IMDB per classificazione binaria del sentiment. Breakdown tecnico completo — tokenizzazione WordPiece, embedding posizionali, self-attention multi-testa, meccanismo Q/K/V, e perché il modello fallisce sul sarcasmo finché non gli dai dati sintetici.
Leggi →
CNN + LSTM per Image Captioning: senza Transformer, senza magie, solo matematica
Prima che i meccanismi di attenzione prendessero il sopravvento, il captioning di immagini si costruiva concatenando un encoder CNN con un decoder LSTM. Spiegazione tecnica completa — convoluzioni, blocchi residui, embedding, memoria con gate. Con formule vere e diagrammi veri.
Leggi →