MLP da zero: 98% di accuratezza sulla classificazione del cancro, senza Keras
Prima di usare PyTorch, dovresti capire cos'è PyTorch. Quindi abbiamo costruito un MLP da zero. Python puro, niente autograd, niente magia da framework. Lo abbiamo fatto girare su un problema reale di classificazione binaria: distinguere tumori al seno maligni da benigni. 569 campioni, 30 feature, 20 configurazioni di iperparametri. Andiamo.
Perché MLP invece della regressione logistica
La regressione logistica funziona. Ma è lineare. Quando la tua ipotesi ha non-linearità, hai due opzioni: ingegnerizzare manualmente feature polinomiali (che fa esplodere lo spazio delle feature in fretta), oppure lasciare che la rete impari da sola quelle rappresentazioni non-lineari.
Un MLP è la seconda opzione. Impara combinazioni non-lineari degli input impilando layer di neuroni, ognuno con una funzione di attivazione non-lineare. Niente feature engineering manuale.
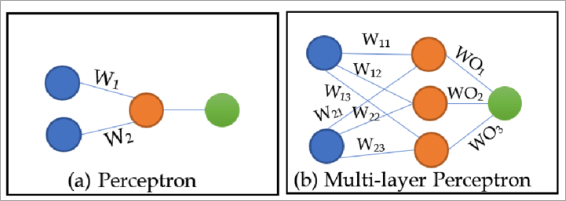
Il neurone artificiale
Ogni neurone prende input e un insieme di pesi, calcola una somma pesata e la passa attraverso una funzione di attivazione:
I pesi determinano quanta attenzione il neurone dà a ogni input. Neuroni diversi nello stesso layer imparano distribuzioni di pesi diverse, costruendo rappresentazioni diverse degli stessi dati. Così la rete può catturare più pattern contemporaneamente.
Perché serve il bias
Prendi la funzione di Heaviside come funzione di attivazione. Se la somma pesata è esattamente 0, il neurone non produce nulla e non impara nulla. Si risolve aggiungendo un termine di bias costante alla combinazione lineare:
Il bias trasla la funzione di attivazione orizzontalmente, permettendo al neurone di attivarsi anche quando gli input da soli non spingono la somma oltre zero.

Architettura
Metti abbastanza neuroni in un layer e ottieni più capacità rappresentativa. Impila i layer e ottieni rappresentazioni gerarchiche. Un MLP è una rete fully connected feed-forward: ogni neurone nel layer si connette a ogni neurone nel layer .
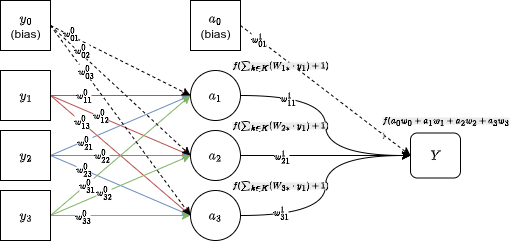
Per questo progetto: 30 feature in input, un hidden layer (di cui varrà la dimensione), un neurone di output. Attivazione sigmoid ovunque perché è classificazione binaria.
Forward propagation
Si spingono gli input in avanti attraverso la rete, calcolando la combinazione lineare e l'attivazione ad ogni layer, fino a raggiungere l'output .
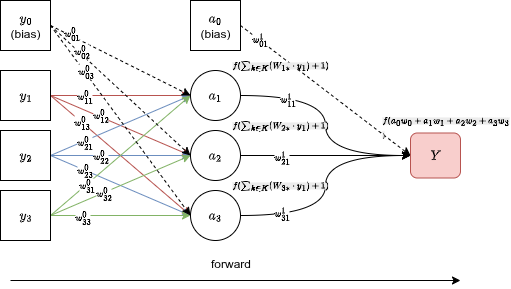
L'output è la tua predizione. Ora devi confrontarla con l'etichetta reale e calcolare un errore .
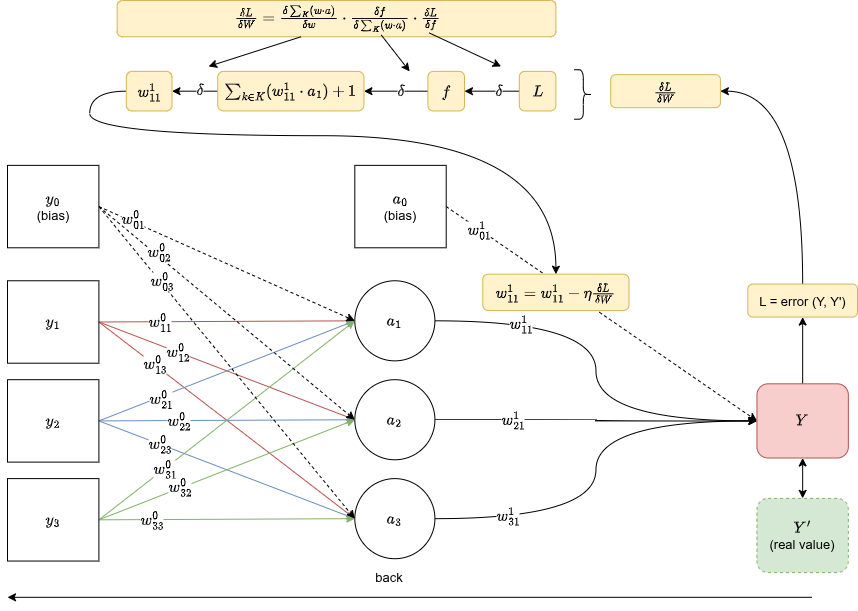
Backpropagation
La backprop è la regola della catena applicata a un grafo computazionale. Hai una loss (errore tra e $Y'$), e vuoi sapere quanto ogni peso ha contribuito a quell'errore, per aggiornarlo nella direzione giusta.
Per ottenere per un peso nel layer , percorri il grafo computazionale all'indietro, concatenando i gradienti ad ogni passo:
Una volta ottenuto il gradiente, aggiorni il peso proporzionalmente:
Dove è il learning rate. Questo è il gradient descent.
Il dataset
Breast Cancer Wisconsin (Diagnostic) da UCI/Kaggle.
- 569 istanze, 30 feature numeriche
- Classi: maligno (212 campioni, 37.3%) vs benigno (357 campioni, 62.7%)
- Feature: misurazioni per nucleo cellulare (raggio, texture, perimetro, area, levigatezza, compattezza, concavità, simmetria, dimensione frattale). Media, errore standard e valore peggiore di ciascuna.
Lo sbilanciamento delle classi (62/38) è abbastanza lieve da non richiedere oversampling, ma devi comunque tracciare sia precision che recall, non solo l'accuracy.
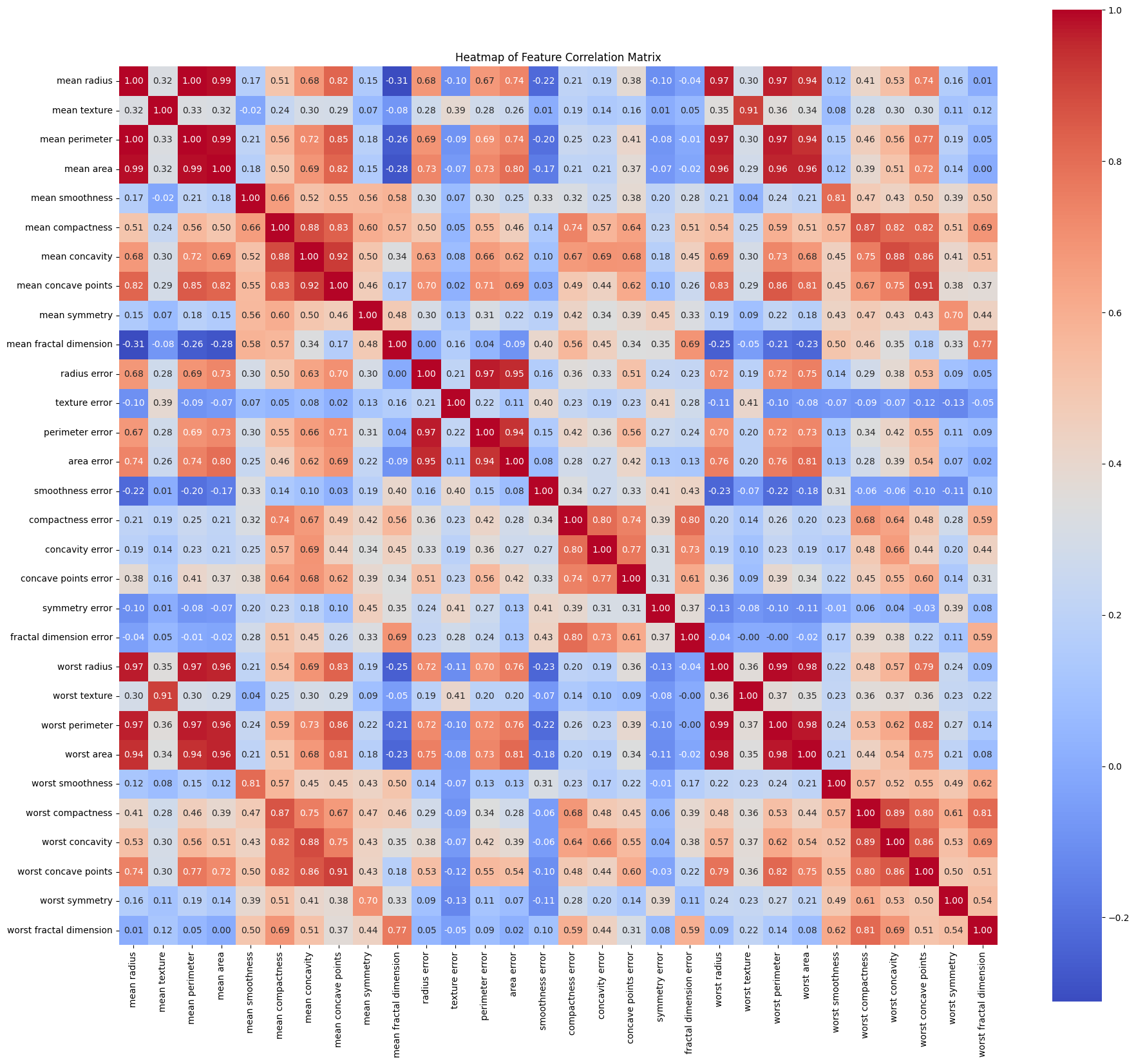
La heatmap rende ovvia una cosa: raggio, perimetro e area sono quasi perfettamente correlate. Stai fornendo alla rete feature ridondanti, ma un MLP lo gestisce. Le pesa semplicemente di conseguenza.
Standardizzazione
Le feature hanno range completamente diversi. L'area media va da 143 a 2501. La levigatezza media va da 0.053 a 0.163. Senza normalizzazione, gli aggiornamenti dei pesi durante il gradient descent sarebbero dominati dalle feature ad alto range.
Soluzione: standardizzare ogni feature a media=0, varianza=1.
Abbiamo usato StandardScaler di sklearn. Una riga, non ha senso riscriverla.
Grid search
Abbiamo eseguito 20 configurazioni: 5 dimensioni dell'hidden layer × 4 learning rate.
- Neuroni nascosti: 2, 5, 15, 30, 50
- Learning rate: 0.01, 0.1, 0.50, 1.5
- Epoche massime: 200
- Early stopping: se la validation loss media supera la validation loss minima per 10 volte consecutive, si ferma
L'early stopping è importante. Senza, si girerebbero sempre tutte le 200 epoche e si sprecherebbe compute su configurazioni che hanno smesso di migliorare alla quindicesima.
Risultati
| Config | Hidden | LR | Epoche | Val Loss | Test Acc |
|---|---|---|---|---|---|
| MLP_H30_LR1.5 | 30 | 1.50 | 12 | 0.0095 | 98.25% |
| MLP_H15_LR1.5 | 15 | 1.50 | 12 | 0.0099 | 98.25% |
| MLP_H15_LR0.1 | 15 | 0.10 | 168 | 0.0122 | 98.25% |
| MLP_H50_LR0.01 | 50 | 0.01 | 200 | 0.0160 | 97.66% |
| MLP_H15_LR0.01 | 15 | 0.01 | 200 | 0.0184 | 97.66% |
Tre configurazioni raggiungono la stessa accuratezza del 98.25% sul test set. La più interessante è il confronto tra MLP_H30_LR1.5 e MLP_H15_LR0.1: stessa accuratezza finale, ma una converge in 12 epoche e l'altra in 168. LR=1.5 è aggressivo, ma qui funziona. Il dataset non è particolarmente complesso. 30 feature, abbastanza separabile linearmente da permettere a una rete piccola con un alto learning rate di trovare il boundary in fretta.
Il lento (LR=0.01, 200 epoche) a malapena recupera, e una rete più larga non compensa un learning rate sbagliato.
Matrice di confusione
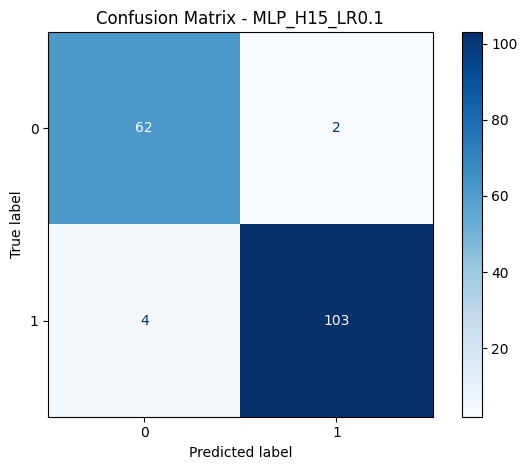
6 errori di classificazione su 171 campioni di test. 4 falsi negativi (maligno classificato come benigno) e 2 falsi positivi. In un contesto medico, i falsi negativi sono quelli costosi. Meglio investigare un caso benigno inutilmente che perdere un maligno.
F1 score (pesato): 0.9650. Precision e recall entrambe intorno a 0.98 per le prime 3 configurazioni.
Confronto: MLPClassifier di sklearn
Abbiamo fatto girare lo stesso dataset con MLPClassifier di sklearn per vedere se la nostra implementazione era competitiva.
| Config | Hidden | LR | Epoche | Test Acc |
|---|---|---|---|---|
| sklearn H50 LR1.5 | 50 | 1.50 | 15 | 96.49% |
| sklearn H15 LR0.5 | 15 | 0.50 | 31 | 96.49% |
Sklearn si ferma al 96.49%. La nostra implementazione da zero la batte di 1.76 punti percentuali. Il gap viene probabilmente dalle differenze nell'ottimizzatore (sklearn usa Adam o SGD con momentum di default, noi gradient descent puro) e da come è implementato l'early stopping. Il risultato tiene: un MLP scritto a mano con gli iperparametri giusti batte una libreria configurata diversamente.
Confronto: Weka
Come riferimento, la stessa architettura in Weka (-L 0.01 -M 0.02 -N 200 -V 30 -S 0 -E 10 -H 15):
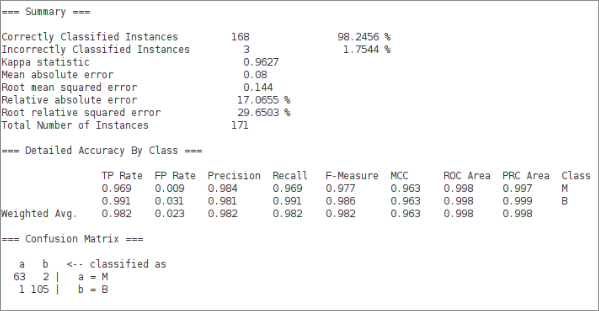
Weka arriva al 98.2456%, sostanzialmente uguale al nostro risultato migliore. Kappa statistic 0.9627, F-measure pesato 0.982. La matrice di confusione è quasi identica: 63 TN, 2 FP, 1 FN, 105 TP.
Cosa ti dicono i risultati
Un MLP a singolo hidden layer con 15 neuroni e LR=1.5 risolve questo problema in 12 epoche. Non è impressionante come complessità del modello. È impressionante come struttura del dataset. La diagnosi del cancro al seno dalla geometria nucleare risulta essere apprendibile con pochissimo compute.
La lezione principale non è "l'MLP è buono". È che la scelta degli iperparametri (soprattutto il learning rate) conta più della dimensione della rete su dati tabulari con feature pulite. Raddoppiare i neuroni da 15 a 30 non cambia nulla. Passare da LR=0.01 a LR=1.5 risparmia 156 epoche.
TL;DR
- MLP: layer di neuroni, ognuno calcola
- Backprop: regola della catena che percorre il grafo computazionale all'indietro
- Dataset: 569 campioni di cancro al seno, 30 feature, classificazione binaria
- Standardizzazione: , obbligatoria prima del gradient descent su feature con scale diverse
- Grid search su 20 configurazioni (dimensione hidden × LR), early stopping con patience 10
- Risultato migliore: 98.25% con H=30, LR=1.5, 12 epoche
- La nostra implementazione batte MLPClassifier di sklearn di ~1.8 punti su questo dataset
- Il learning rate conta più della larghezza della rete