CNN + LSTM per Image Captioning: senza Transformer, senza magie, solo matematica
Lo so, nel 2026 tutti usano ViT + GPT-4o per generare descrizioni di immagini in due righe di Python. Il punto è questo: se non capisci le pipeline pre-transformer, non capisci davvero cosa succede dentro quelle moderne. Il meccanismo di attenzione è solo una versione migliore di quello che stiamo per descrivere.
Quindi abbiamo costruito un sistema di image captioning da zero. ResNet50 come encoder, LSTM come decoder, addestrato su Flickr8k. Nessun modello linguistico pre-addestrato. Nessun embedding CLIP. Solo convoluzioni, moltiplicazioni di matrici e celle di memoria con gate. Andiamo.
L'architettura in una frase
Un encoder CNN (ResNet50) estrae feature spaziali da un'immagine e le comprime in un vettore a 256 dimensioni. Un decoder LSTM prende quel vettore e genera una didascalia, parola per parola.
L'output dell'encoder viene concatenato con le caption embeddate e dato in pasto a un LSTM per generare la frase corrispondente. Fine. Tutto il resto sono dettagli implementativi. Vediamo i layer uno ad uno.
Parte 1: La convoluzione
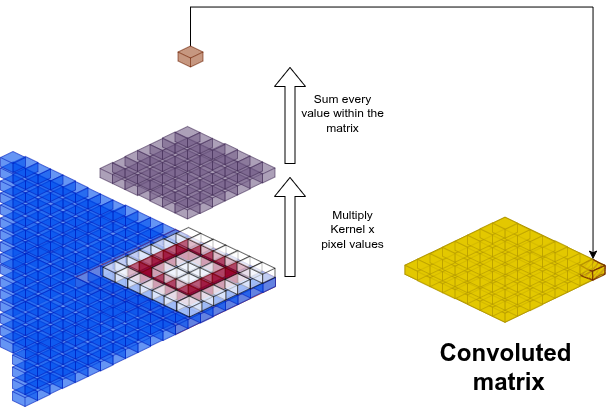
Prendi un'immagine composta da pixel in bianco e nero. Puoi scrivere l'intensità come numeri. Ogni cubo qui sotto è un numero da 0 a 255.

Definisci un kernel come una piccola matrice di pesi apprendibili usata per estrarre feature dall'immagine.
Una convoluzione è una combinazione lineare tra i pixel dell'immagine e uno o più filtri:
sono le coordinate di output nella matrice convolta. Il risultato è una cella di una nuova matrice più piccola: la feature map. Il kernel estrae pattern locali: bordi, gradienti, angoli.
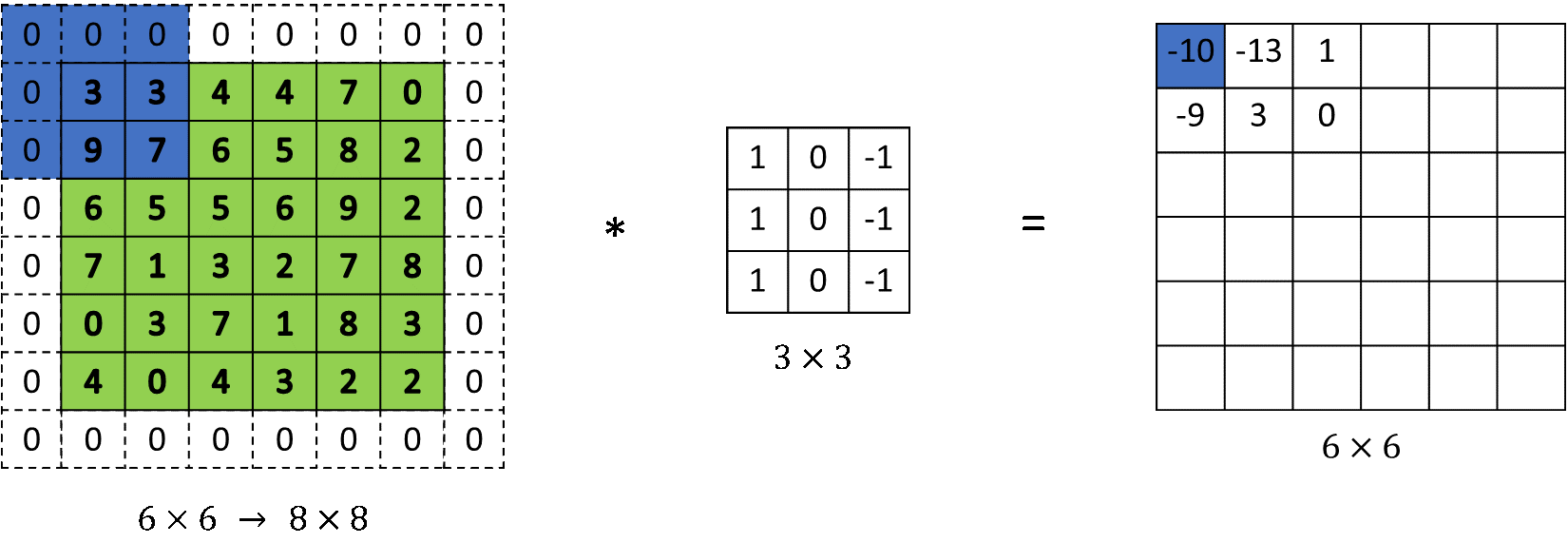
Stride e Padding
- Stride : di quanti pixel si sposta il kernel ad ogni passo
- Padding : aggiunge zeri ai bordi per controllare le dimensioni dell'output
Data un'immagine e un kernel , la dimensione dell'output è:
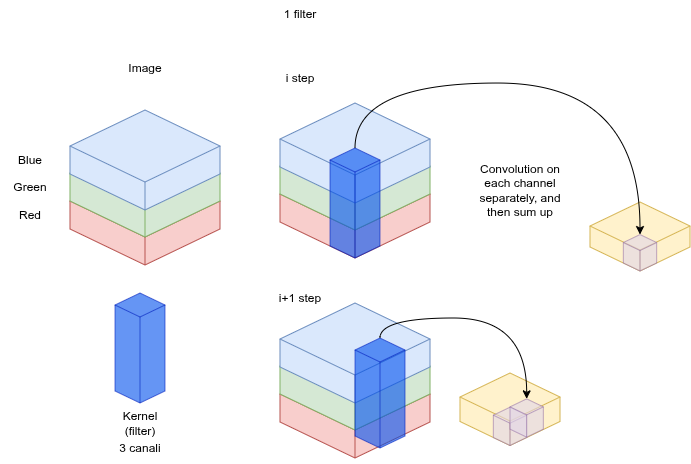
Immagini a colori: 3 canali
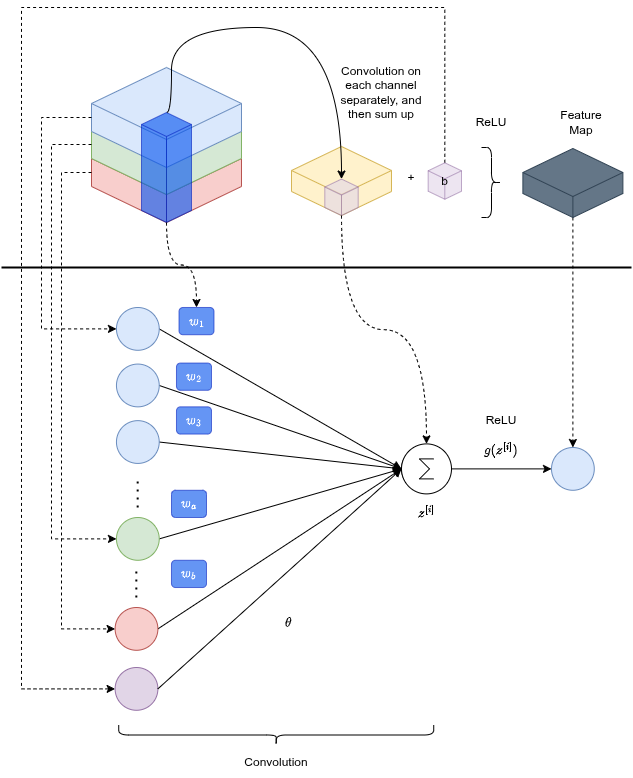
Per le immagini RGB si applica il kernel su ciascun canale (R, G, B) separatamente, poi si sommano i risultati:
Aggiungendo più filtri si ottengono più canali (feature) per descrivere l'immagine.
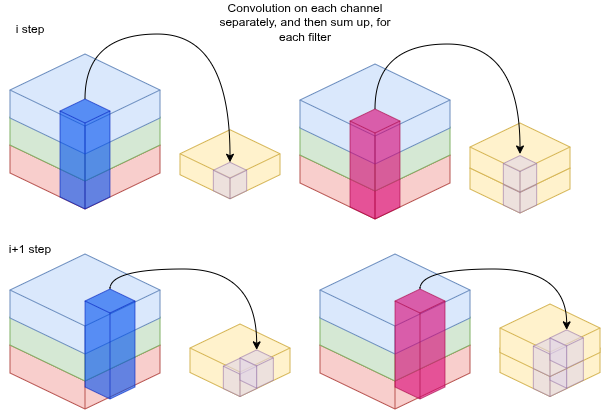
L'intera idea di una CNN è trasformare un'immagine in un vettore di feature.
Layer convoluzionale
Prendi la matrice di feature dalla convoluzione (operazione lineare), aggiungi un bias, applica ReLU (non lineare). È come una rete neurale dove i nodi di input sono le intensità dei canali sotto il kernel e i pesi sono i valori del kernel. Il bias evita che la funzione sia forzata a passare per l'origine, permettendo alla rete di rappresentare pattern con un offset.
Pooling Layer
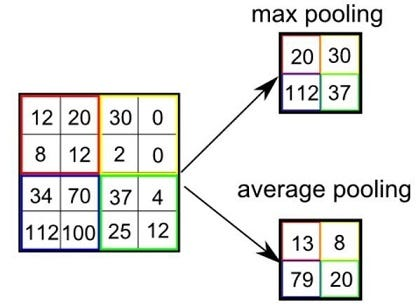
Il max pooling prende il massimo in ogni finestra. L'average pooling fa la media. Entrambi riducono le dimensioni spaziali, aggregano le feature e contrastano direttamente l'overfitting.
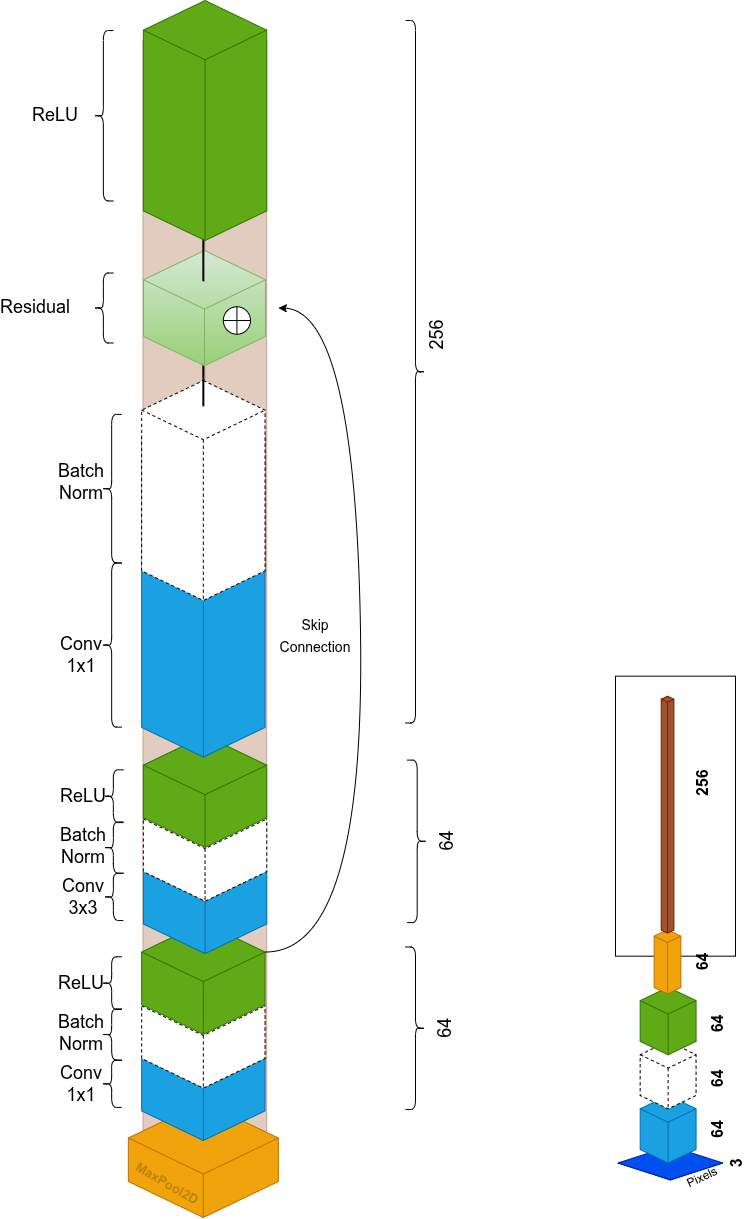
Parte 2: ResNet50, l'encoder
ResNet50 è la nostra backbone per l'estrazione di feature. Trasforma le immagini in input in rappresentazioni significative attraverso uno stage iniziale e quattro stage di blocchi residui. Nello stage di flattening finale, rimuoviamo l'head di classificazione per preservare le feature map invece di produrre predizioni di classe.
Perché "Res"?
"ResNet" sta per Residual Network. L'idea centrale: invece di imparare una mappatura completa, i layer imparano il residuo: la differenza tra input e output desiderato. Una skip connection bypassa uno o più layer e aggiunge direttamente l'input originale all'output.
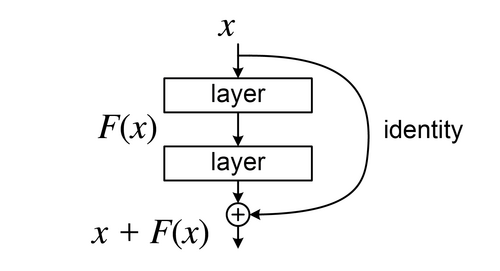
I gradienti scorrono direttamente attraverso la skip connection durante la backprop. Questo risolve il problema del vanishing gradient e rende pratico addestrare reti con 50+ layer.
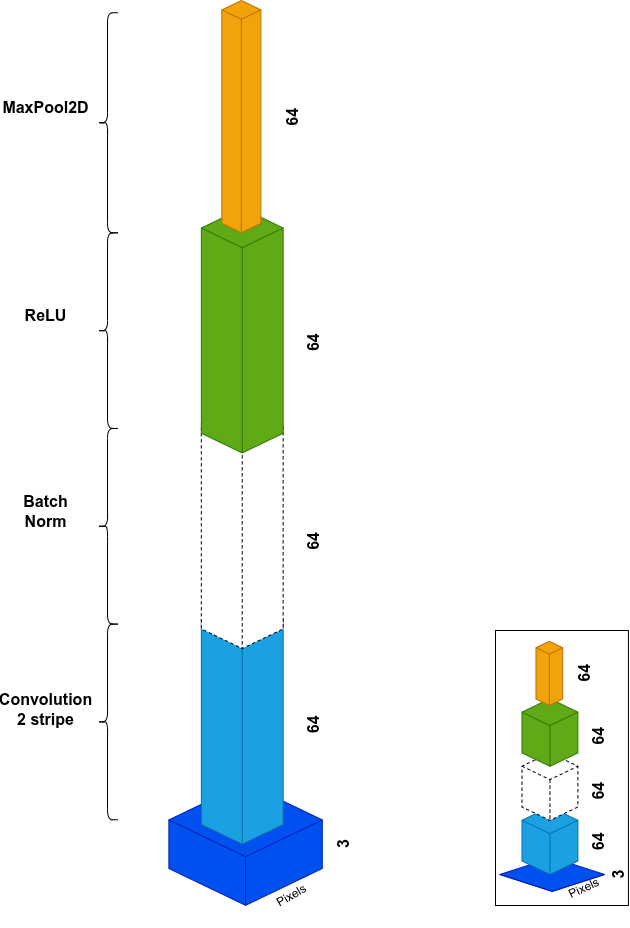
Stage iniziale
- Conv 7×7, stride 2 → dimezza la risoluzione spaziale, elimina il rumore dei pixel
- BatchNorm → media 0, varianza 1, stabilizza i gradienti
- ReLU → non-linearità, azzera i negativi
- MaxPool 3×3, stride 2 → ulteriore downsampling 2×, aggiunge invarianza alla traslazione (gli spostamenti piccoli non cambiano il massimo, le feature restano robuste)
Blocchi residui Bottleneck
Ogni blocco residuo ha 3 convoluzioni, il design bottleneck:
| Passo | Operazione | Scopo |
|---|---|---|
| 1 | Conv 1×1 | Riduce i canali (comprime il calcolo) |
| 2 | Conv 3×3 | Estrae contesto spaziale |
| 3 | Conv 1×1 | Ripristina/espande le dimensioni |
La skip connection aggiunge l'input originale all'output. Quando le dimensioni non corrispondono (es. 64 → 256), una conv 1×1 sul percorso skip gestisce la proiezione.
Dopo il primo stage, ogni nuovo stage aumenta la complessità semantica scambiando risoluzione spaziale per profondità di canale. La conv 3×3 usa stride=2 per dimezzare le dimensioni spaziali estraendo feature spaziali:
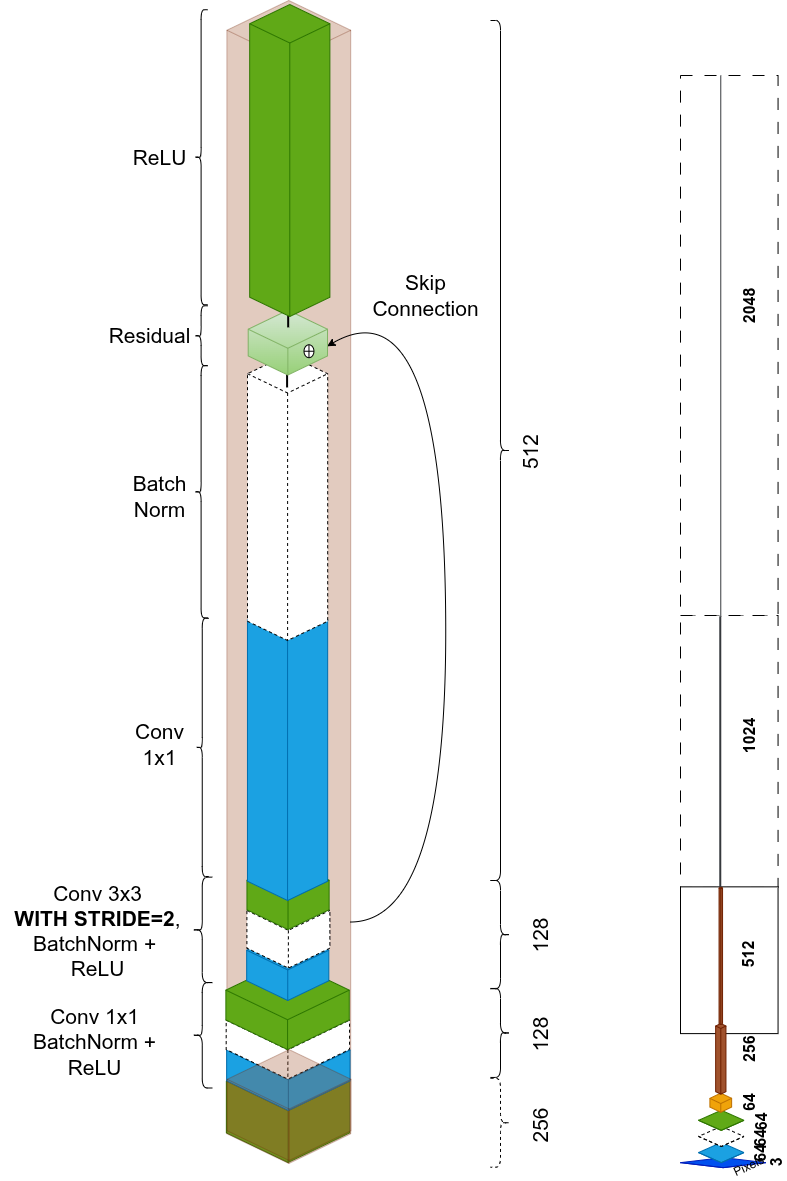
Ripetizioni per stage, trovate ottimali sperimentalmente: 3 → 4 → 6 → 3 blocchi. Output finale: 2048 canali a 7×7.
Stage di flattening
Dopo 2048 canali a 7×7, ResNet fa una compressione finale:
- Adaptive Average Pooling: collassa tutti i 49 pixel spaziali (7×7) in un singolo valore per canale tramite media. Mantiene solo l'essenza semantica.
- Proiezione lineare: converte lo spazio di feature da 2048 a 256:
- BatchNorm: normalizza l'embedding per metriche di distanza stabili.
Risultato: un compatto fingerprint a 256 dimensioni dell'immagine.
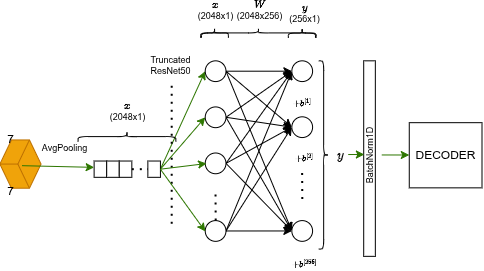
Questo embedding finale alimenta il decoder LSTM.
Parte 3: Decoder
Vocabolario
Le parole con frequenza < 5 vengono scartate. Token speciali aggiunti: <PAD> (padding per uniformare la lunghezza delle sequenze), <START>, <END>, <UNK> (sconosciuto per le parole scartate). Vocabolario finale: 5.507 parole.
Embedding Layer
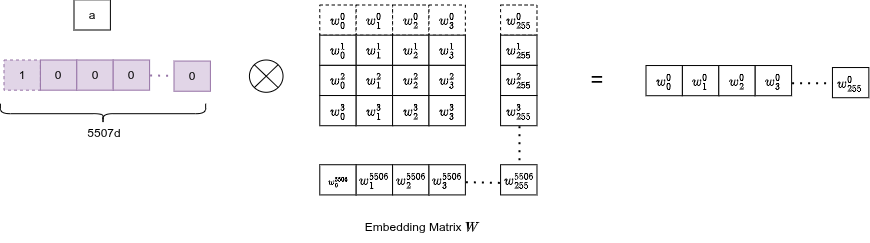
Una lookup table apprendibile: matrice di dimensione .
Ogni parola mappa a un indice intero → una riga di . L'embedding è addestrato end-to-end, quindi parole semanticamente simili ("cane", "gatto") finiscono con vettori vicini nello spazio 256-d.
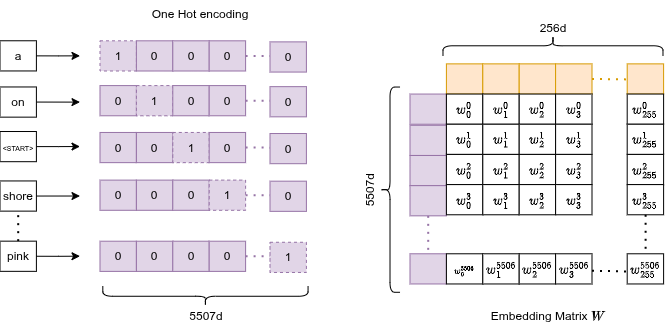
Poiché le parole sono one-hot encoded internamente, la moltiplicazione matriciale collassa in una semplice selezione di riga: viene selezionata esattamente la riga corrispondente della matrice:
Concatenazione
Il vettore immagine funge da primo token a . Gli embedding delle parole seguono in sequenza:
sequenza = [vettore_immagine | parola_0 | parola_1 | ... | parola_T]
Le feature dell'immagine fungono da input iniziale, seguite dagli embedding delle parole. Questo è ciò che alimenta l'LSTM.
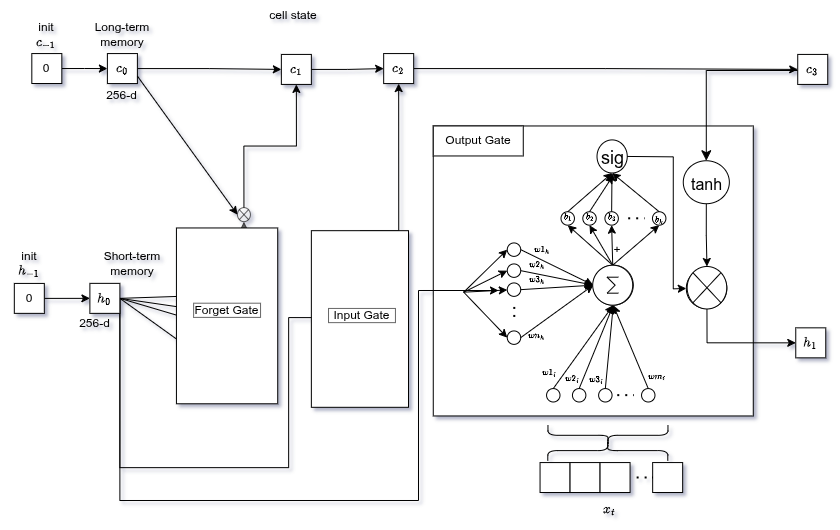
Parte 4: LSTM
Usiamo la Long Short-Term Memory invece di una RNN classica per due ragioni:
- Il modello deve ricordare l'immagine (vista a $t=0$) fino alla fine della frase. Serve memoria a lungo termine.
- Le LSTM mitigano il vanishing gradient su sequenze lunghe tramite la struttura a gate.
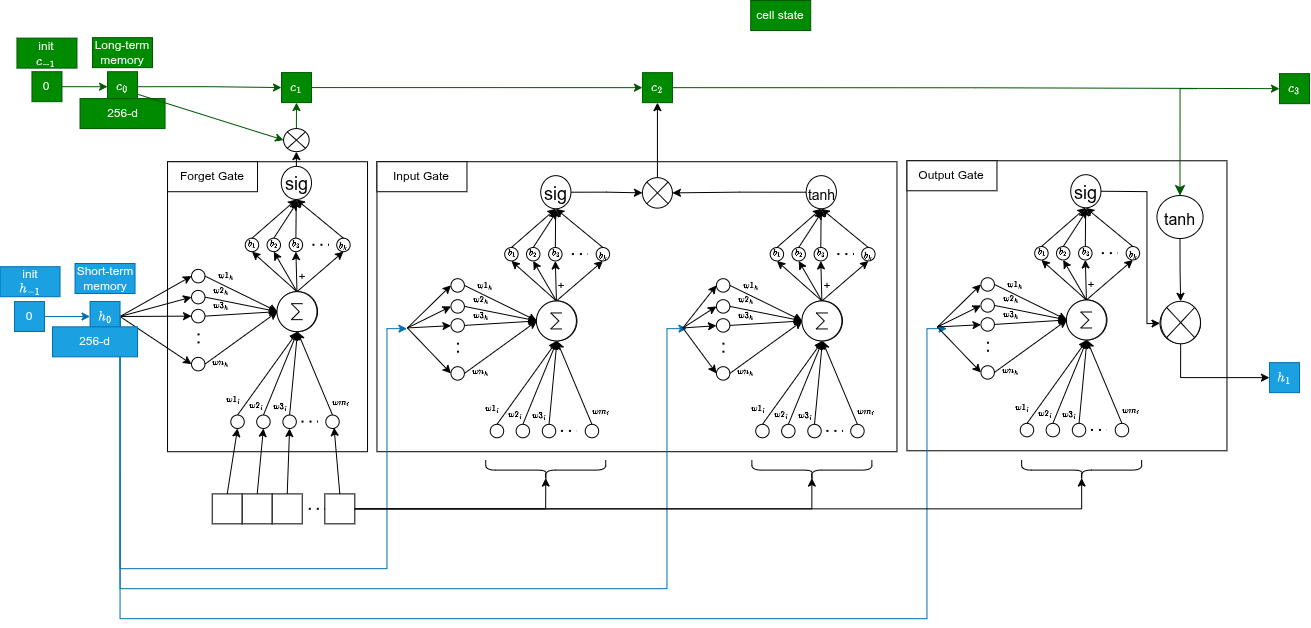
Due stati scorrono nel tempo:
- Hidden state (256-d): memoria a breve termine, output visibile, usato per predire la prossima parola
- Cell state (256-d): highway della memoria a lungo termine, trasporta info cruciali (es. il soggetto dell'immagine) senza degradarsi
A , gli stati sono inizializzati a zero e il vettore immagine è il primo input.
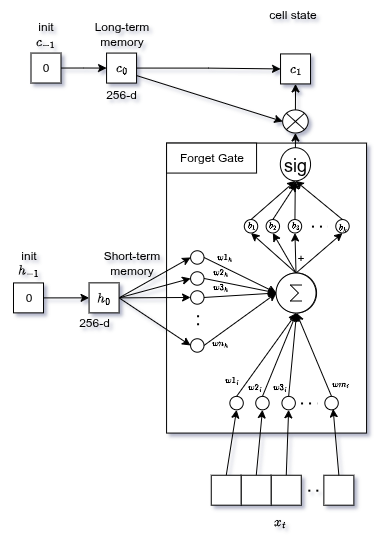
Forget Gate
Decide quali informazioni dalla memoria passata ($C_{t-1}$) non servono più.
Guarda l'input corrente e il precedente hidden state , moltiplica ciascuno per i propri pesi, somma, aggiunge bias, passa tutto a una sigmoid:
Output: valori 0 (dimentica) → 1 (mantieni) per ogni elemento del cell state.
Dopo aver generato "uomo", il gate potrebbe dimenticare la feature generica "soggetto presente" per liberare memoria per il verbo.
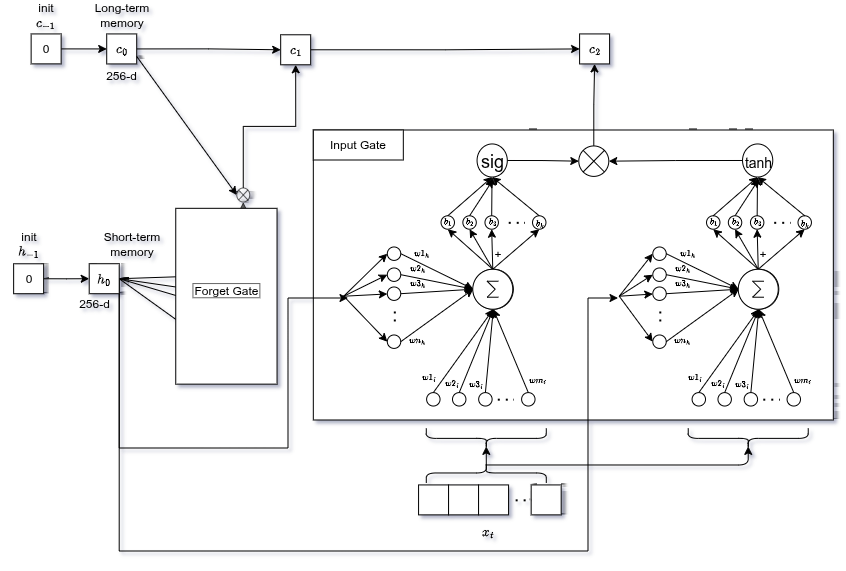
Input Gate
In parallelo, decide quali nuove informazioni scrivere nella memoria a lungo termine.
- Rete
tanh→ valori candidati (range −1 a +1, es. intensità della feature singolare/plurale) - Rete
sigmoid→ quanto è importante ogni candidato (0 a 1)
Moltiplica entrambi, aggiungi alla memoria precedente gated:
La vecchia memoria viene aggiornata: dimentichiamo il vecchio, sommiamo il nuovo pesato per importanza.
Output Gate
Decide quale deve essere il prossimo hidden state (memoria a breve termine).
sigmoid decide quali parti del cell state mandare in output. Poi passa per tanh (spinge i valori tra −1 e +1) e viene moltiplicato per l'output della sigmoid:
La memoria sa che il soggetto è "gatto singolare", ma se dobbiamo predire un verbo, l'output gate filtra solo l'informazione "singolare" per coniugare correttamente.
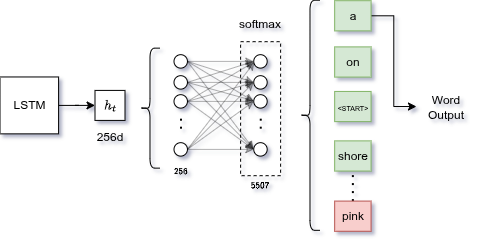
Layer Fully Connected finale
L'output LSTM (256-d) è un concetto astratto. Dobbiamo tradurlo in una parola del vocabolario.
Linear layer: la matrice pesi proietta l'hidden state su un vettore delle dimensioni del vocabolario.
- Training: Cross Entropy Loss confrontando i logits con la parola reale successiva (teacher forcing: si usa la parola reale al tempo come input per lo step $t+1$)
- Inferenza: si passano i logits per softmax, si sceglie la parola con probabilità più alta, la si ri-usa come input successivo
Training
Dataset: Flickr8k: 8.000 immagini, 5 caption ciascuna = 40.000 coppie.
Strategia: Teacher forcing. Si usa la parola reale della caption al tempo come input per lo step . Forza il modello ad imparare predizioni corrette invece di accumulare i propri errori durante il training.
Data augmentation per epoch per forzare l'apprendimento di concetti visivi robusti:
- Crop e resize casuali
- Flip orizzontale
- Color jitter (luminosità/contrasto)
- Leggere rotazioni
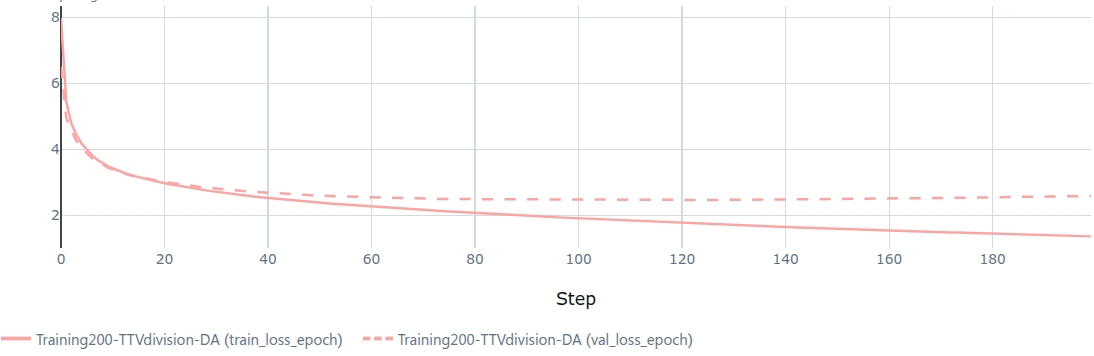
Risultati
La training loss è diminuita costantemente. La validation loss si è stabilizzata intorno all'epoch ~150, poi è leggermente aumentata. Overfitting moderato.



Soggetti, azioni e contesti sono identificati correttamente. Sintatticamente un po' grezzo in certi punti, ma semanticamente sensato. Non male senza nessun modello linguistico pre-addestrato.
Il collo di bottiglia architetturale
Ecco il difetto: tutta l'informazione visiva deve passare attraverso un singolo vettore a 256 dimensioni. Alla quinta parola, il modello sta generando "bicicletta" ma l'encoding dell'immagine è diluito su tutto quello che ResNet ha mai visto.
I meccanismi di attenzione risolvono questo: invece di un singolo vettore riassuntivo, il decoder può interrogare le feature map spaziali di ResNet (7×7 × 2048) ad ogni step, focalizzandosi sulla regione dell'immagine rilevante. Il modello chiede "quale parte dell'immagine è rilevante adesso?" Questo è il passo successivo.
TL;DR
- ResNet50: immagine → vettore 256-d (convoluzioni + blocchi residui + adaptive pooling + proiezione lineare)
- Embedding layer: parole → vettori 256-d (addestrati end-to-end, semanticamente significativi)
- LSTM:
[immagine, parola_0, parola_1...]→ distribuzione sulla prossima parola (3 operazioni di memoria con gate ad ogni step) - Cross entropy loss + teacher forcing durante il training
- Lieve overfitting dopo epoch 150, output coerenti
- Il collo di bottiglia del singolo vettore è il difetto architetturale → l'attenzione è la soluzione